Apache Iggy's migration journey to thread-per-core architecture powered by io_uring
By grzegorz
Introduction
At Apache Iggy, performance is one of our core principles. We take pride in being blazingly fast, pushing our systems to reach the absolute limits of the underlying hardware, eventually exhausting all available options within our previous architecture. Thus, a new approach was needed. If you're an active Rust Reddit user, you may have already seen this discussion. It predates this blog post, and we wanted to use it as an opportunity to explore the thread-per-core shared-nothing architecture powered by io_uring in more depth.
Rationale
To explain the "whys" of that decision in detail, a quick primer on the status quo is needed.
Apache Iggy utilized tokio as its async runtime, which uses a multi-threaded work-stealing executor. While this works great for a lot of applications (work stealing takes care of load balancing), fundamentally it runs into the same problem as many "high-level" libraries: a lack of control.
When tokio starts, it spins up N worker threads (typically one per core) that continuously execute and reschedule Futures. The scheduler decides on which worker a particular Future gets to run, which can lead to task migrations between workers, cache invalidations, and less predictable execution paths. While Rust Send and Sync bounds prevent data-race undefined behavior, they do not prevent higher-level concurrency bugs such as deadlocks.
But even these challenges weren't what finally tipped us over the edge. The way tokio handles block device I/O was the real dealbreaker. Tokio, following the poll-based Rust Futures model, uses (depending on the platform) a notification-based mechanism to perform I/O on file descriptors. The runtime subscribes for a readiness notification for a particular descriptor and awaits the readiness in order to submit the I/O operation. While this works decently well for network sockets, it's completely incompatible for block devices. The Linux kernel considers regular files to be always "ready" for reading or writing, meaning epoll (or similar notification mechanisms) will immediately return, and the subsequent I/O operation will block the executing thread anyway (on page-cache lock contention or other kernel operation). To overcome this issue, tokio relies on a thread pool approach. It outsources every block device I/O operation to a shared blocking thread pool, where threads are spawned on demand. By default, tokio allows this blocking thread pool to grow up to 512 threads. A high-performance system can quickly exhaust the capabilities of such a thread pool (leaving aside the overhead from servicing 512 threads), which is why we concluded that tokio doesn't scale for our needs.
Thread per core shared nothing architecture
The thread-per-core shared-nothing architecture is what we landed on when it comes to improving the scalability of Apache Iggy. It has been proven to be successful by high-performance systems such as ScyllaDB and Redpanda, both of those projects utilize the Seastar framework to achieve their performance goals.
In short, the core philosophy behind this approach is to pin a single thread to each CPU core, partition your resources based on a heuristic (commonly hashing), eliminate shared state, thereby reduce lock contention and improve cache locality and finally, use message passing for communication between those threads, also known as shards in Seastar terminology. Sounds like a good plan, but as with everything, the devil is in the details.
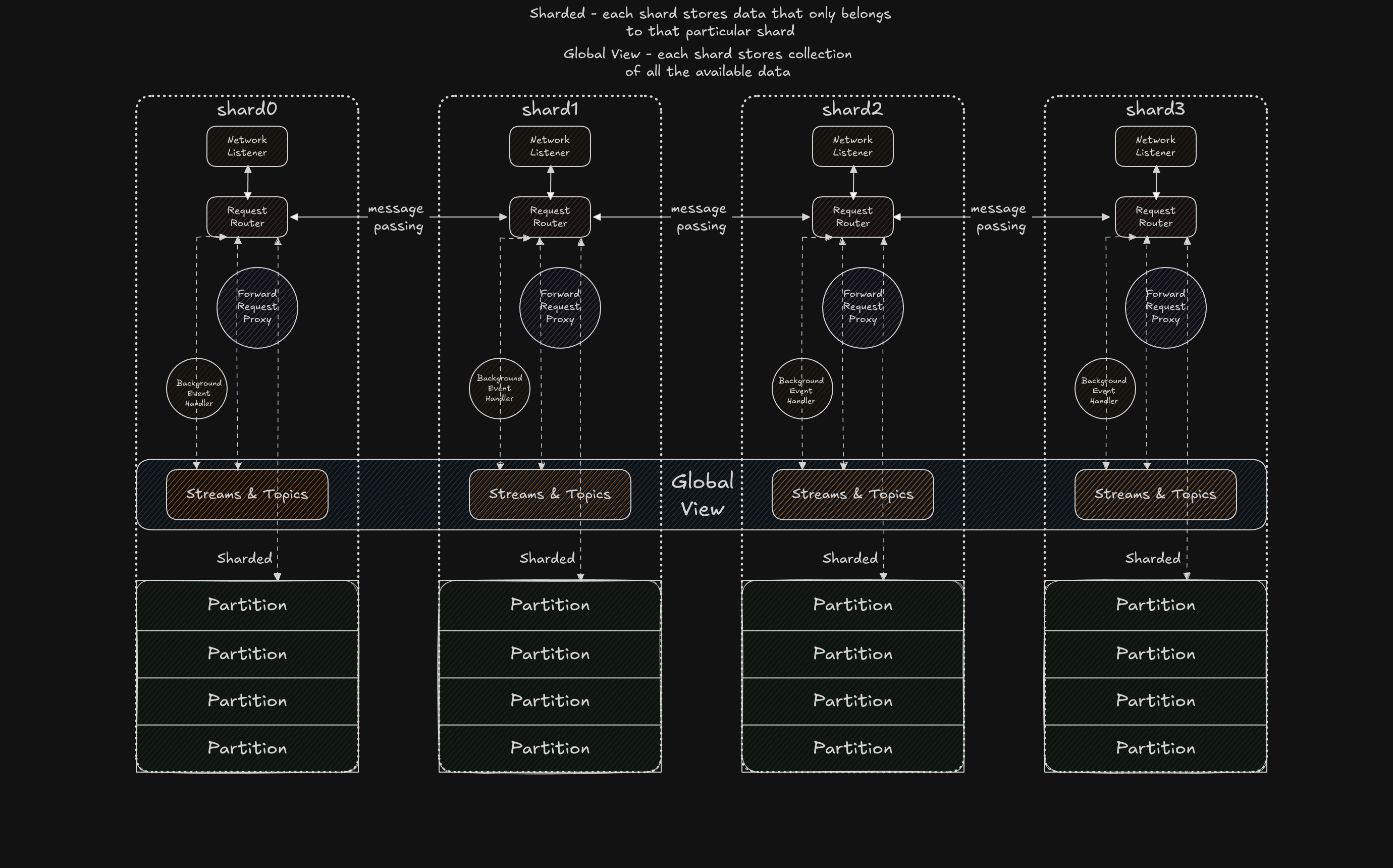 From a bird's-eye view, this architecture solves the primary issues of our previous approach: we move from work stealing to work steering. That's a big W, but we were still left with block-device I/O. Using a thread pool for file operations would ultimately negate the performance gains from core pinning, so we needed a truly asynchronous I/O interface, and that is how we discovered
From a bird's-eye view, this architecture solves the primary issues of our previous approach: we move from work stealing to work steering. That's a big W, but we were still left with block-device I/O. Using a thread pool for file operations would ultimately negate the performance gains from core pinning, so we needed a truly asynchronous I/O interface, and that is how we discovered io_uring.
There is plethora of materials regarding io_uring as it's the hot thing, but very briefly the interface is straightforward, io_uring rather than being a notification system (readiness based), it's completion-based, you submit the operation and the kernel drives it to completion. The core mechanism revolves around two lock-free ring buffers shared between user space and the kernel: the Submission Queue (SQ), where your application enqueues I/O requests, and the Completion Queue (CQ), where the kernel places the results once the operations are done. Since that model isn't compatible with how Rust Future works (Futures are poll-based), the initial poll of the Future is used for the submission of the request. A continuation via callback model would fit the completion I/O paradigm better, but it comes with its own caveats, nevertheless the overhead from the impedance mismatch is negligible. As for the awaiting part, it's a simple peek into the CQ, looking for a completion entry that matches the polled Future at hand (io_uring allows attaching a usize user_data cookie to each submission, which is used to identify the corresponding user-space Future and wake it up). Everything else, let's pretend for a moment, is magic.
Pick your poison
With all the design pieces in place, it was time to visit the marketplace of async runtimes. We evaluated 3 candidates:
monoioglommiocompio
All of them support io_uring as the driver, some exclusively, others as one of several available ones.
Using the FIFO order - monoio was our choice for the initial proof-of-concept, it worked pretty well, but as we explored the monstrous API surface of io_uring, we realized that it's pretty far behind when it comes to feature parity and doesn't appear to be very actively maintained. Don't get us wrong, the runtime still receives patches, especially after incidents like this, but the overall pace of development doesn't keep up with a rapidly evolving interface like io_uring.
Next on the list glommio - this one is particularly interesting as it was initially developed by Glauber Costa, who previously worked at ScyllaDB, the creators of the Seastar framework, glommio significantly differs from the other two runtimes on our list. It's still a thread-per-core runtime, but it uses a proportional-share scheduler, creates 3 io_uring instances per thread (a main ring, a latency ring, and a polling ring), and ships with quite a lot of high-level APIs (similar to Seastar) that one can use. Unfortunately, it followed the same fate as monoio, it's pretty much unmaintained at this point. On top of that, it's fairly opinionated as a runtime, and we disagreed with some of those opinions (more on that later).
Finally, compio - this is what we ended up using. It's very similar to monoio in terms of architecture, but it stands out for its broad io_uring feature coverage, active maintenance (our patches got merged within hours), and its codebase structure. Unlike monoio, the compio codebase is structured in a way where the driver is disaggregated from the executor, meaning that one can build their own executor while still reusing the io_uring driver.
Notably, compio boxes the I/O request that is submitted to the SQ, which means that every I/O request incurs a heap allocation, something that monoio avoids. In our case, it's not that big of a deal, as those allocations are very small and mimalloc is quite good at maintaining a pool for small, predictable allocations. We did raise the question in their Telegram channel about whether it would be feasible to use a Slab allocator the approach that monoio takes, but the authors decided against it, as it would introduce a lot of complexity into the executor, which uniformly supports other drivers such as Windows IOCP.
Devil's speech
Remember how we mentioned that the devil is in the details? Let's give him mic now.
At first glance since the thread-per-core shared-nothing model all state is local to each shard and anything that requires a global view must be replicated across shards via message passing, it looks like a perfect candidate for Interior mutability, replace your Mutexes with RefCells and run with the quick win. If you thought that, I've got bad news, you'd be greeted straight from the ninth circle of Dante's Inferno with:
thread 'shard-8' (496633) panicked at core/server/src/streaming/topics/helpers.rs:298:21: RefCell already borrowed
Turns out that holding a RefCell borrow across an .await point can cause runtime borrow panics, there is even a clippy lint for that - clippy::await_holding_refcell_ref.
The Rust wg-async (async working group) seems to be aware of that footgun and describes it in this story. It feels like it should be possible to express statically-checked borrowing for Futures using primitives such as GhostCell, they even share a proof-of-concept runtime that does exactly that, but achieving an ergonomic API indistinguishable from normal Rust would probably require significant changes to the compiler and the Context passed with Futures.
We didn't give up (yet) on interior mutability, rather, we reasoned about the underlying problem and attempted to solve it with a better API.
The issue is that during .await points, the executor can potentially yield the execution context to another Future, and that other Future may attempt to borrow the same RefCell, causing a panic at runtime since the borrow from the first Future is still active. We ran into this often because our data structures followed an OOP-style of compile time hierarchy that matches the domain model, which looked akin to that.
struct Stream {
id: usize,
name: String,
storage: Storage
}
impl Stream {
async fn save(&mut self) {
// Do smth with `name` field ...
self.storage.save().await; // <-- Non-Mutable borrow
}
}
// .....
struct Server {
streams: RefCell<Vec<Streams>>,
}
impl Server {
async fn save_stream(id: usize) {
// Holding the `BorrowMut`
let streams = self.streams.borrow_mut();
let stream = streams.iter_mut().find(|s| s.id == id).unwrap();
// Await oopsie.
stream.save().await;
}
}The save procedure can be split into two parts
- The mutation of the in-memory state
- The I/O operation using
storage
This way our RefCell can be much more granular, we use it only for the in-memory representation of Stream, while the storage is stored out of bounds, but for that, we needed a bigger gun, let us introduce ECS (Entity Component System).
One might be familiar with ECS from game engines, not from message streaming platforms, personally I think the general idea behind ECS - SOA (Struct of arrays) is fairly underrated in general.
What we did is split the Entities (Streams, Topics, Partitions, etc.) into their components, where each component is stored in its own dedicated collection.
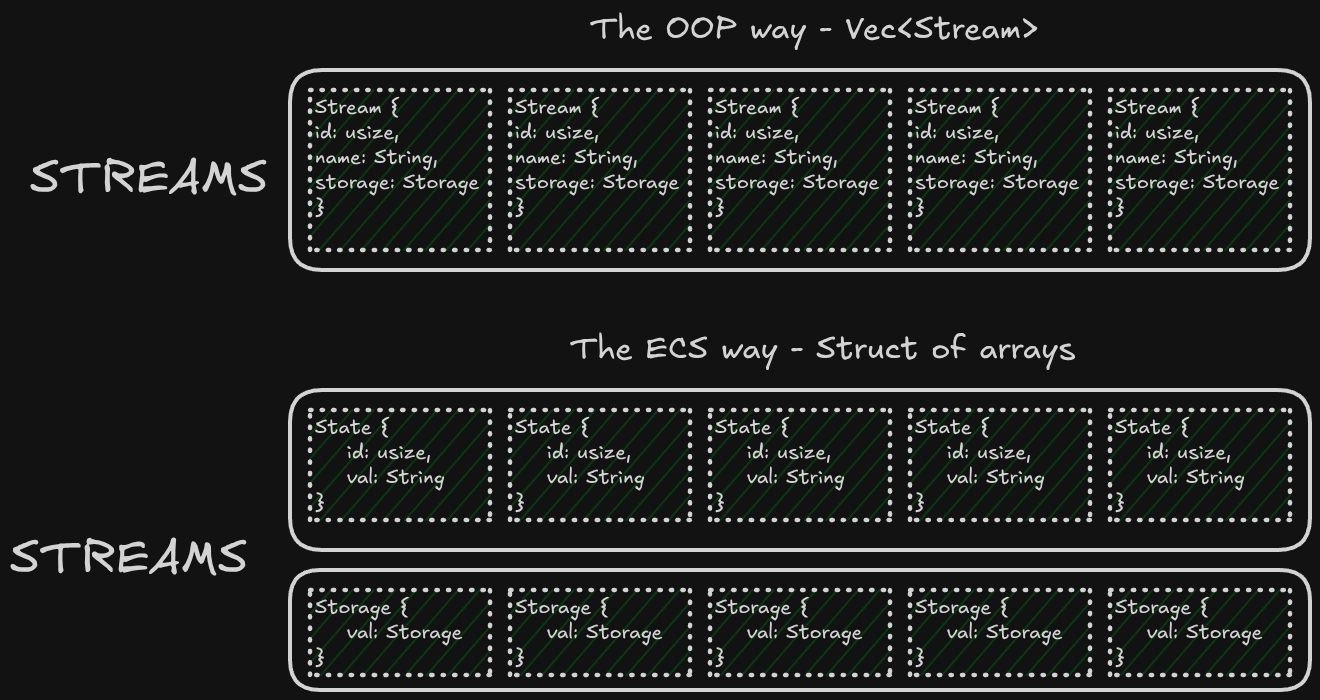
In this case, our components are State and Storage. This allows us to write:
struct Streams {
states: Vec<RefCell<State>>
storages: Vec<Storage>,
}
impl Streams {
async fn save_stream(id: usize) {
self.with_component_by_id_mut(id, |mut states| {
// Update the in-memory representation.
});
// AsyncFn closures just got stabilized while we were working on this
// what a coincidence :)
self.with_component_by_id_async(id, async |storage| {
storage.save().await;
}).await;
}
}We accompany the Streams ECS with component closures that statically disallow async code inside a mutable borrow and voilà.
Well, this approach crumbles just as miserably as the naive attempt...
The thread-per-core shared-nothing architecture requires broadcasting events whenever state changes on one shard. For example, if shard-0 receives a CreateStream request, once it finishes processing, it broadcasts a CreatedStream event through a channel to all other shards. On the receiving end, each shard has a background task that polls this channel for incoming events. The crux of the issue lies in the word background.
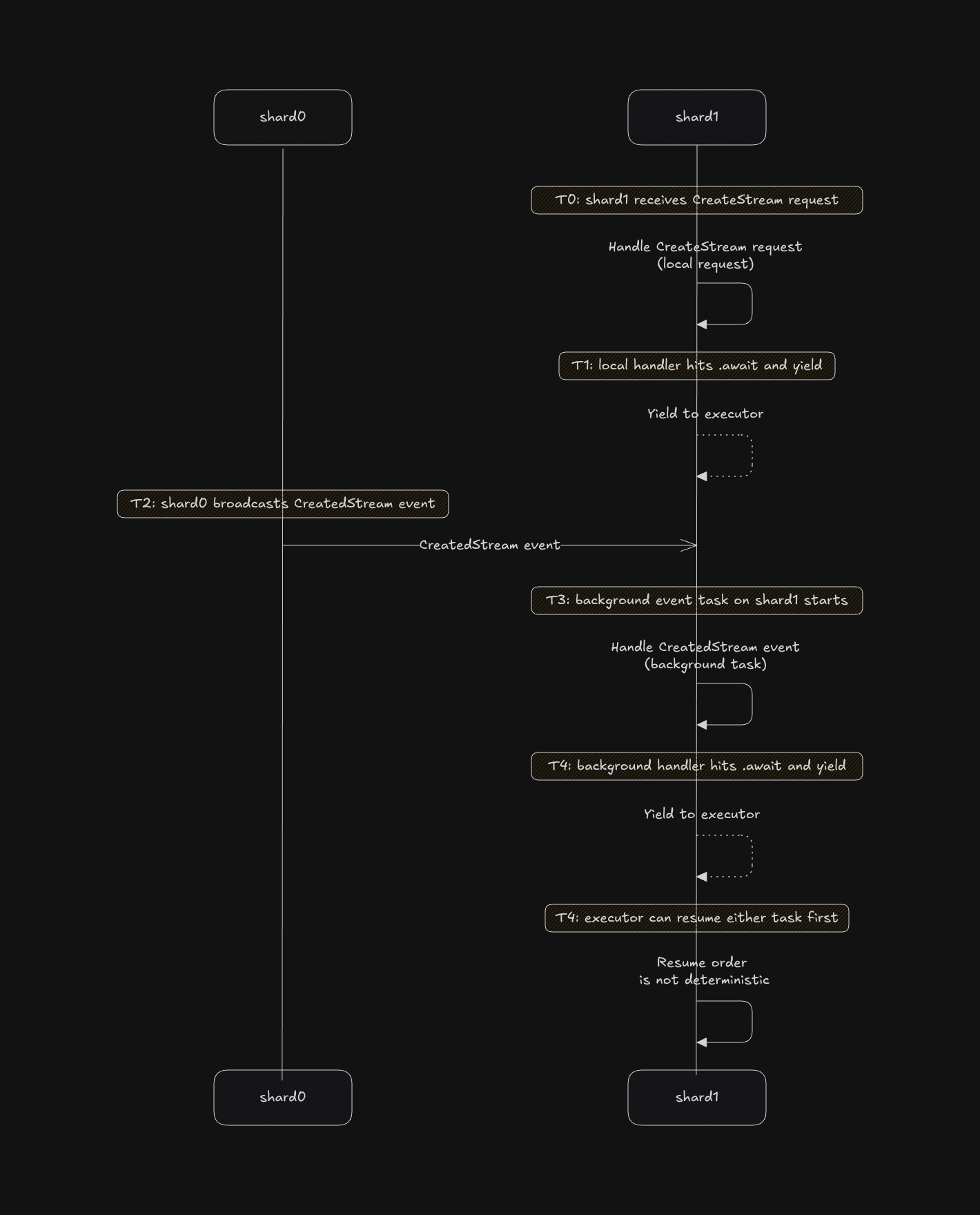
In our Streams example, it might not look like a big deal, but in reality our other Entities were much more complicated, without even introducing other background workers that weren't necessary as part of the thread-per-core shared nothing architecture. A solution to this problem could be using async lock, but those can be footguns aswell.
To our surprise, the issue persisted even in scenarios where we enforced a single-writer principle (we dedicated one shard to become the serialization point for all requests), which was the final nail in the coffin that led us to conclude the experiment as failure. Maintaining a non-shared but consistent state is much more difficult, than just use message passing bro.
Thread per core shared something architecture™
All roads lead to a Mutex — but much more sophisticated one.
After a long fight with interior mutability, we gave up on trying to make fetch happen. Instead, we doubled down on the artifact from the previous iteration (the single-writer principle). We divided our resources into two groups: shared, strongly consistent resources and sharded, eventually consistent ones. An example of a sharded resource is Partition, while Streams and Topics remain shared and strongly consistent, this split later on coined name (Control Plane/Data Plane).
For shared resources, we decided to use left-right, a concurrent data structure designed for a single writer and multiple readers. It works by maintaining two pointers to the underlying data: one for readers and one for the writer. During a writer commit, those pointers are swapped atomically (greatly simplifying). The single writer is the first shard - shard0, while remaining shards have an read handle to the data. In case if a shard other than shard0 would like mutate the data, it sends the request to shard0 using flume channel.
As for our partitions, we maintain one shared table (DashMap) called shards_table that functions as barrier to fence requests that would try to access Partition that is in the process of creation/deletion, the requests are still routed to appropriate shard that contains the Partition, but by consulting the shards_table (during the routing and after the routing), we make sure that the eventual consistency does not come to bite us.
More caveats
This design turned out to be a can of worms, or a bottomless pit, if you prefer. There are plenty more questions to answer, for example, load balancing. In the tokio case, this was fairly simple because it was handled by the task-stealing executor. In our case, if access patterns are unpredictable and some shards become hotspots, we have to deal with that ourselves, a true double-edged sword. A theoretical optimization that we may employ in the future is to shard certain partitions across two or more shards, as proposed by withoutboats - thread-per-core blog post
One can imagine others ways to architect a share-nothing system that may mitigate these forms of imbalance (such as caching hot keys on additional partitions).
We can exploit the fact that our Partition uses segmented log, thus the partition can be sharded even harder based on the segment range and knowledge of which segments are sealed.
Getting the performance benefits out of io_uring itself is a challenge on its own (it's not enough to just swap tokio with an io_uring based runtime), in order to fully take advantage of the benefits from the io_uring design one has to heavily batch syscalls, as this is the main advantage of such interface (less context switches, from userspace to kernel space), Rust Futures can be composed together pretty well to facilitate that, but you have to be careful!
The following code snippet, submits two I/O operations in one "batch", but io_uring does not guarantee that the submission order = completion order!
This "chain" can potentially execute out of order and if your server would crash halfway through, your block device state is broken.
let file = compio::fs::open("foo.bar").await.unwrap();
let content = "some".to_vec();
let content1 = "bytes".to_vec();
// Now batch together those two writes
let write1 = file.write_all(content)
let write2 = file.write_all(content1);
join!(write1, write2).await;To submit a batch while preserving operation order, one must use the io_uring chaining flag IOSQE_IO_LINK on the submitted SQEs, which brings us to the next point.
The state of Rust async runtimes ecosystem
The problem is twofold: at the time of writing this blog post, there is no Rust equivalent of the Seastar framework. That is unfortunate because glommio attempted to be one, but things changed: Glauber moved on to work on Turso, and the Datadog team does not seem to be actively maintaining the runtime while building a real-time time-series storage engine in Rust for performance at scale. They mention sharding a lot there, but why did they decide to use tokio, when they own a runtime that seems like a perfect fit for what they are trying to achieve?
Secundo problemo is that these runtimes imitate the std library APIs, which is POSIX compliant, while many of io_uring's most powerful features are not, leaving those capabilities out of reach for us mere mortals. Request chaining is only the tip of the iceberg, there is plenty more, for example oneshot APIs for listen/recv, registered buffers, and so on. Ultimately, File, TcpListener, and TcpStream are not the right abstractions. From the point of view of POSIX compliance they are, but we cannot allow POSIX to hold us all hostage.
It seems like we are not the only ones that are aware of that problem: Microsoft recently announced a thread-per-core async runtime, that uses Operation as the unit of abstraction, this is a much better idea.
It's worth noting that one of the key reasons we ended up going with compio is that they want to move with the wind of time by exposing more and more io_uring APIs. Their codebase is structured so that the driver is decoupled from the executor, I would push the pluggability even further. A very hot topic in distributed systems these days is DST (Deterministic Simulation Testing): the idea is to replace all non-deterministic sources in your system (network, block devices, time, etc.) with deterministic ones, so that one can re-run the entire execution of the system from a single seed value. At this moment, with async Rust, it is very difficult, if not borderline impossible, to achieve total determinism. The main factor is that one cannot easily replace, for example, the time wheel used for timeouts in those executors. If library authors designed their executors so you could plug in different implementations of the time wheel, scheduler, and driver interceptors for network/storage, we could fully test our systems deterministically, with zero changes needed to the underlying codebase. No need for interfaces behind Storage, no need for timeout managers that have to be replaced with deterministic ones; we could use all of the goodies that come from the Rust Futures model while maintaining the ability to test our systems deterministically.
Benchmarks
Scaling is where the thread-per-core architecture truly shines, the more partitions and producers you throw at it, the better it performs.
Each benchmark is interactive, and clicking on the image will take you to its full report on our site benchmarks.iggy.apache.org.
8 Partitions
v0.5.0 with tokio
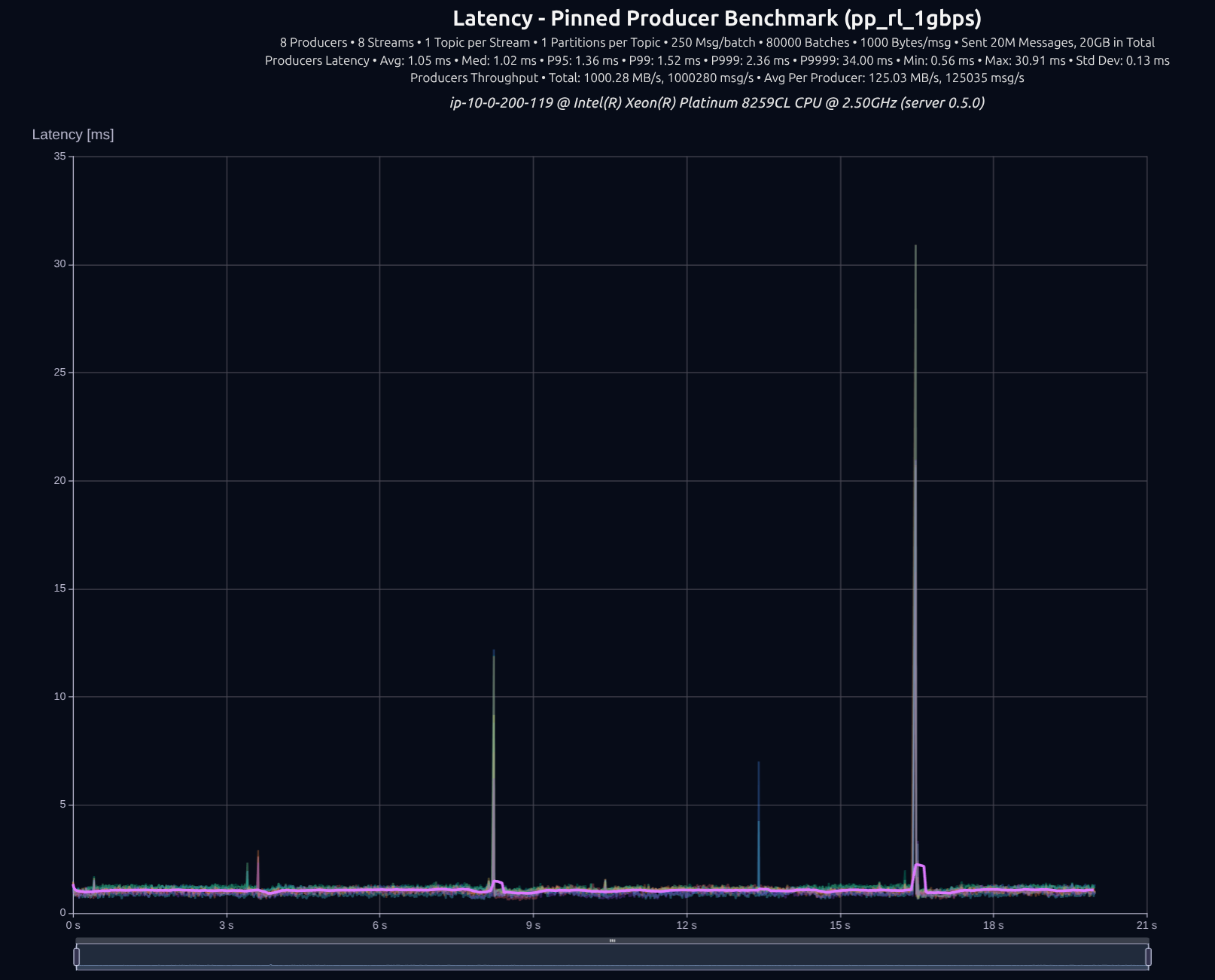
v0.6.1 with thread-per-core + io_uring
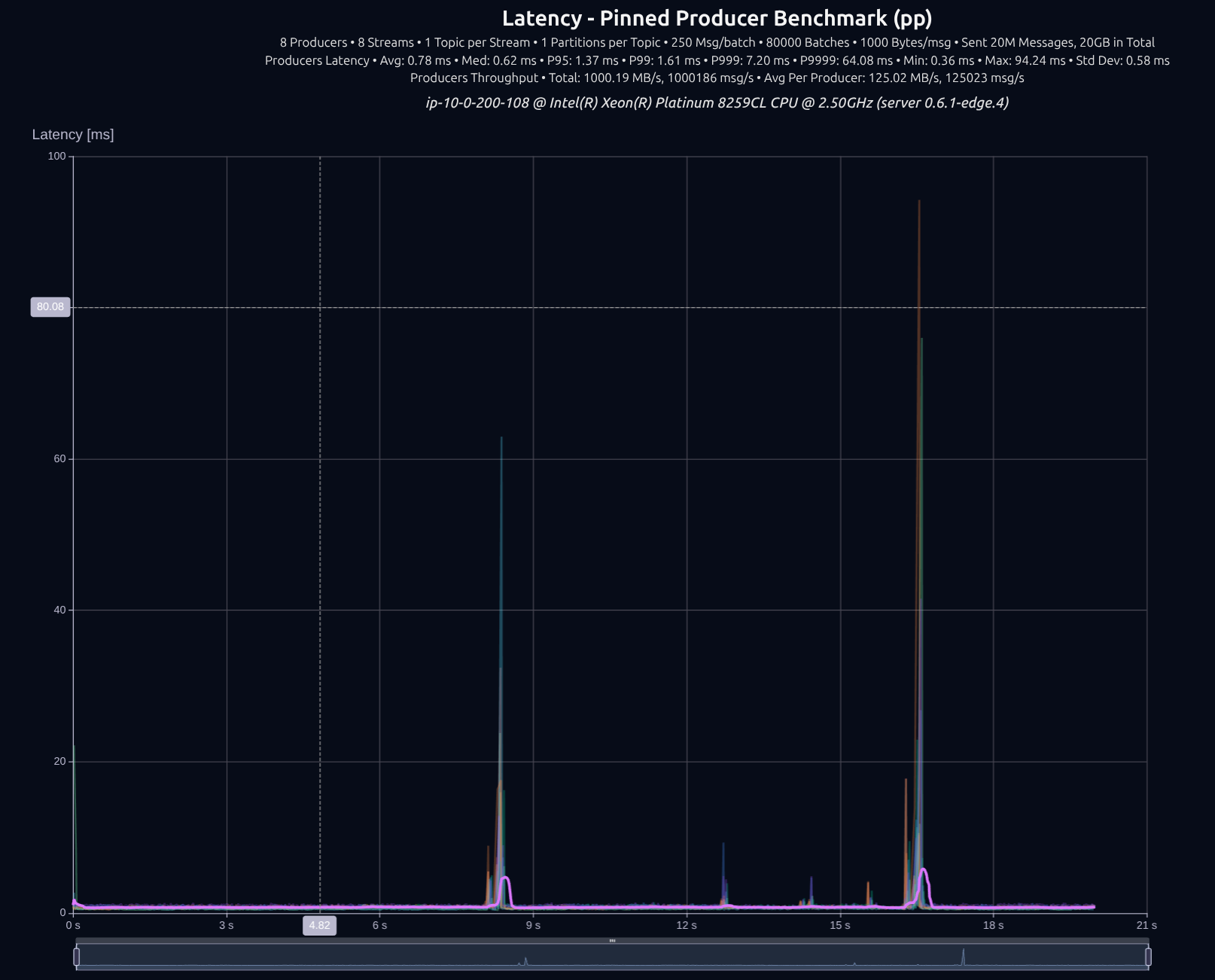
v0.7.0 with shared something
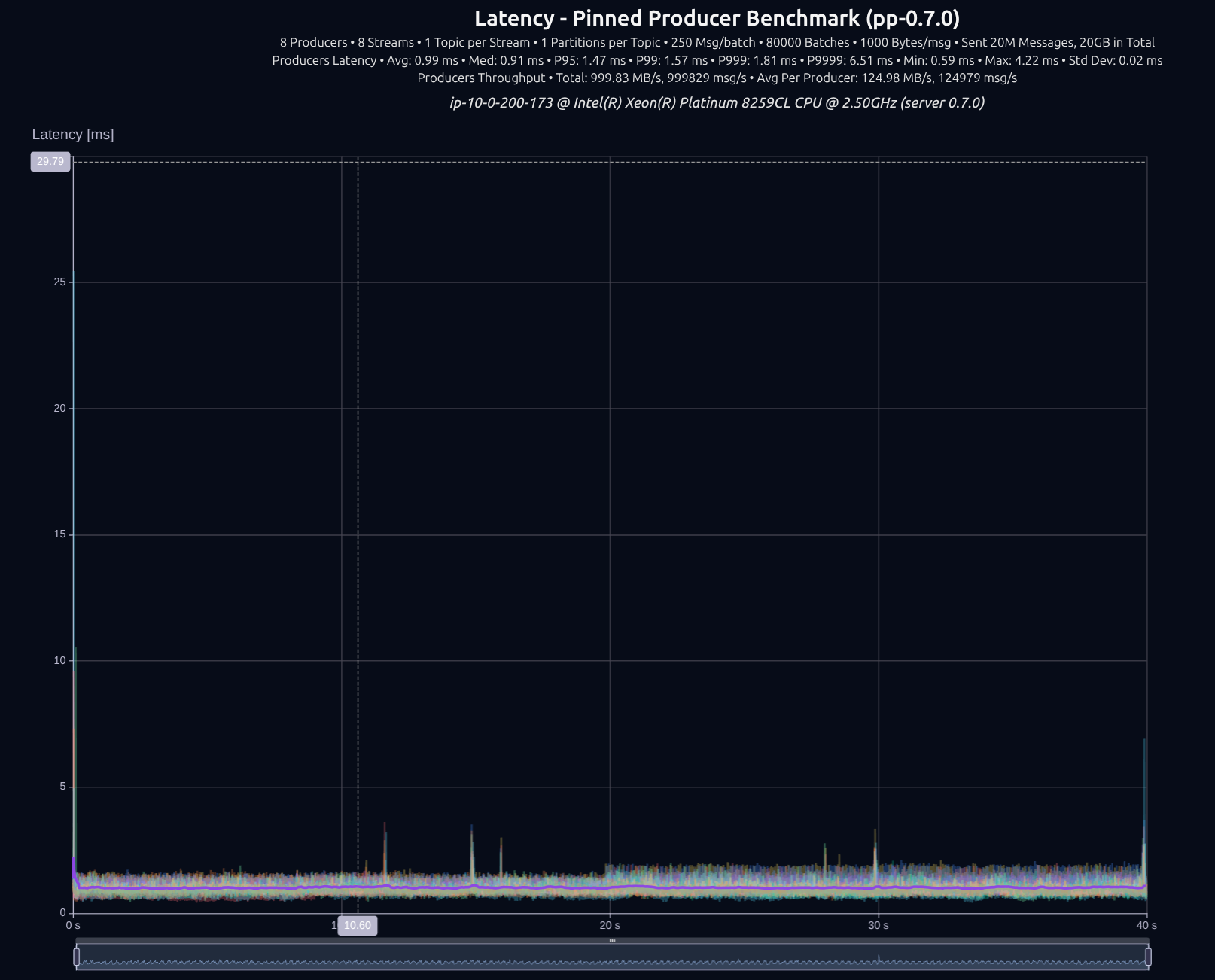
The difference wasn't that big, tokio managed to keep up decently well with 8 producers, but as we increase the load, the gap widens significantly.
8 Producers × 8 Streams — 20 GB (20M msgs)
| Version | Throughput/node | P95 | P99 | P999 | P9999 |
|---|---|---|---|---|---|
| v0.5.0 | 1,000 MB/s | 1.36 ms | 1.52 ms | 2.36 ms | 34.00 ms |
| v0.7.0 | 1,000 MB/s | 1.47 ms | 1.57 ms | 1.81 ms | 6.51 ms |
| Improvement | — | +8% | +3% | -23% | -81% |
16 Partitions
v0.5.0 with tokio
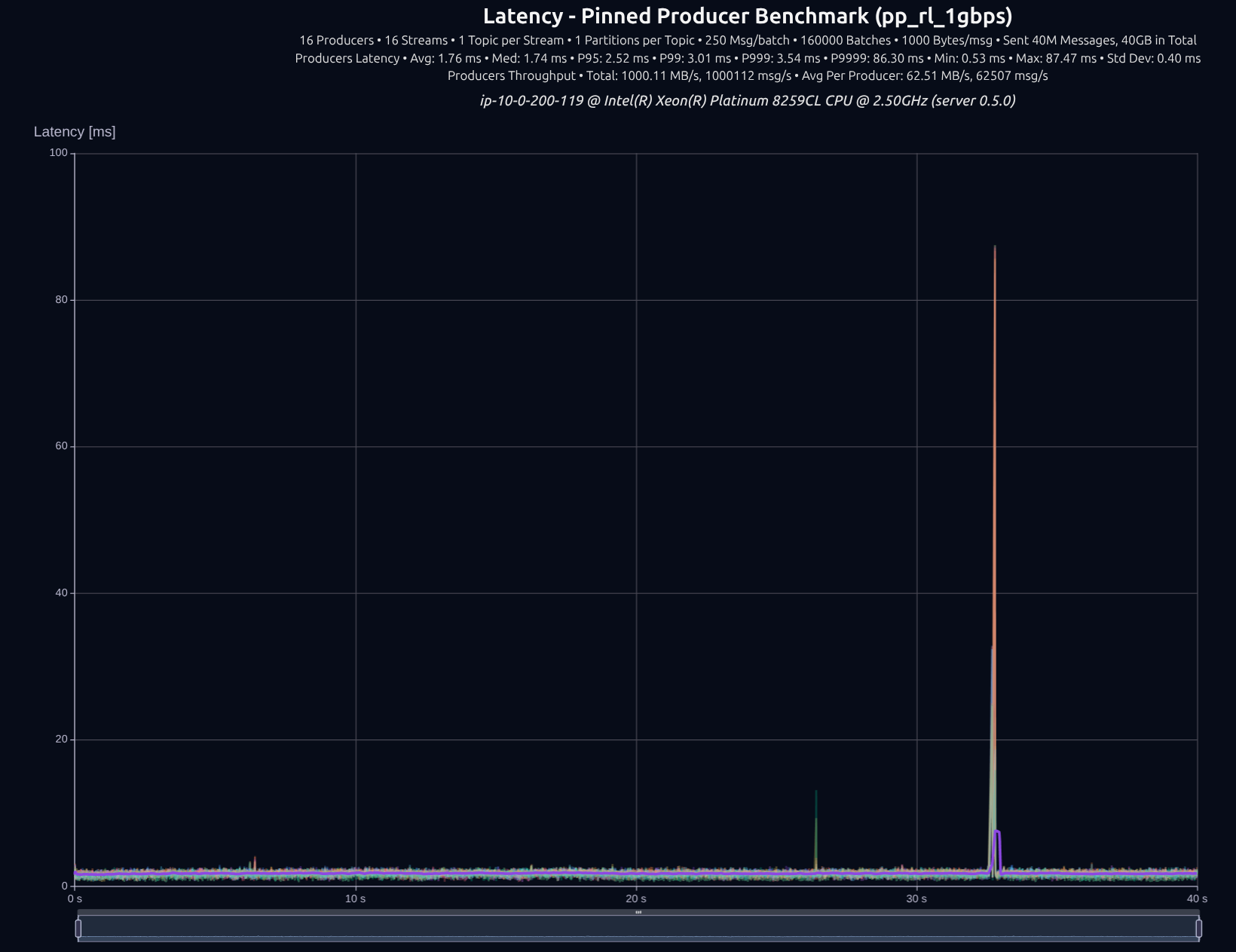
v0.6.1 with thread-per-core + io_uring
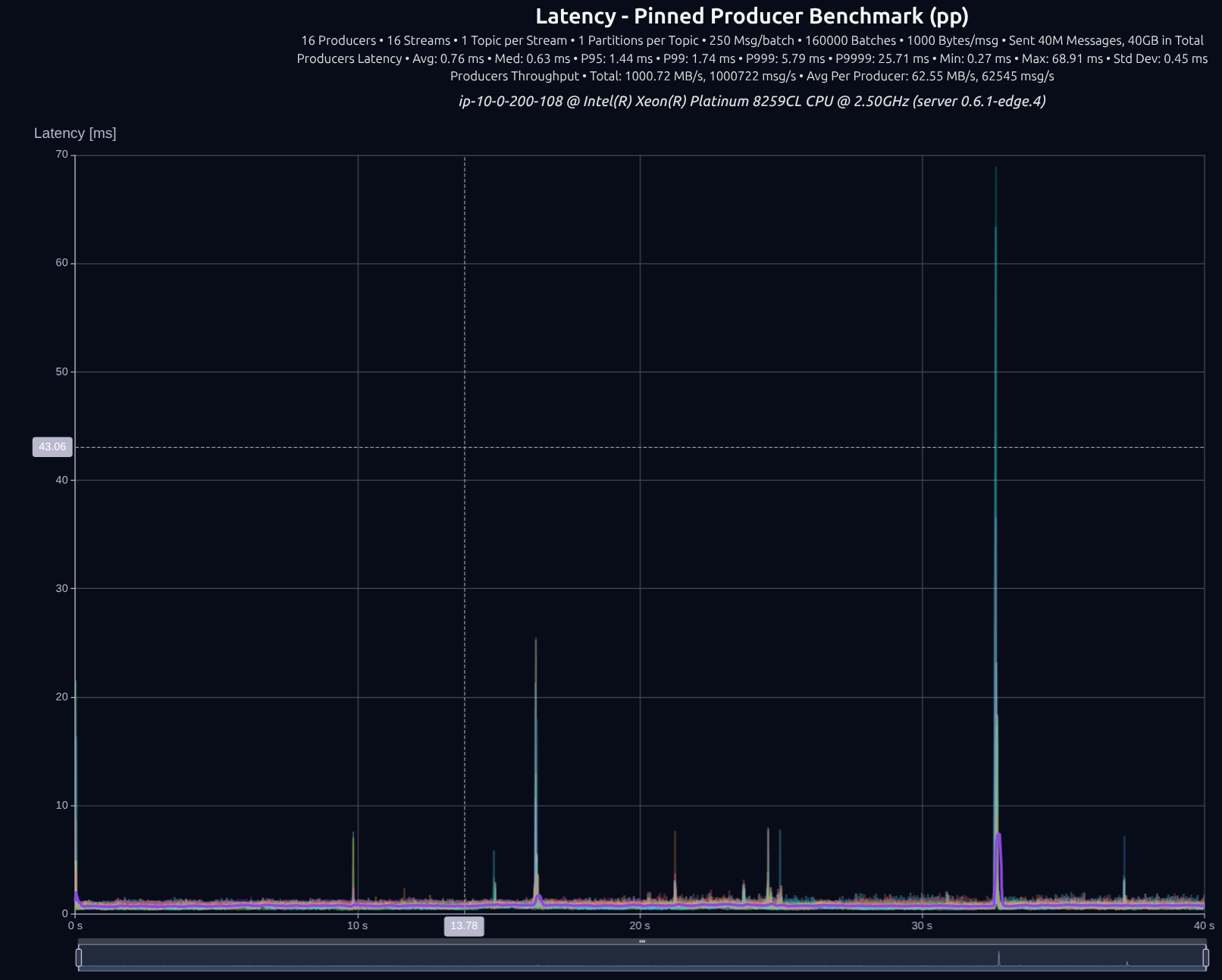
v0.7.0 with shared something
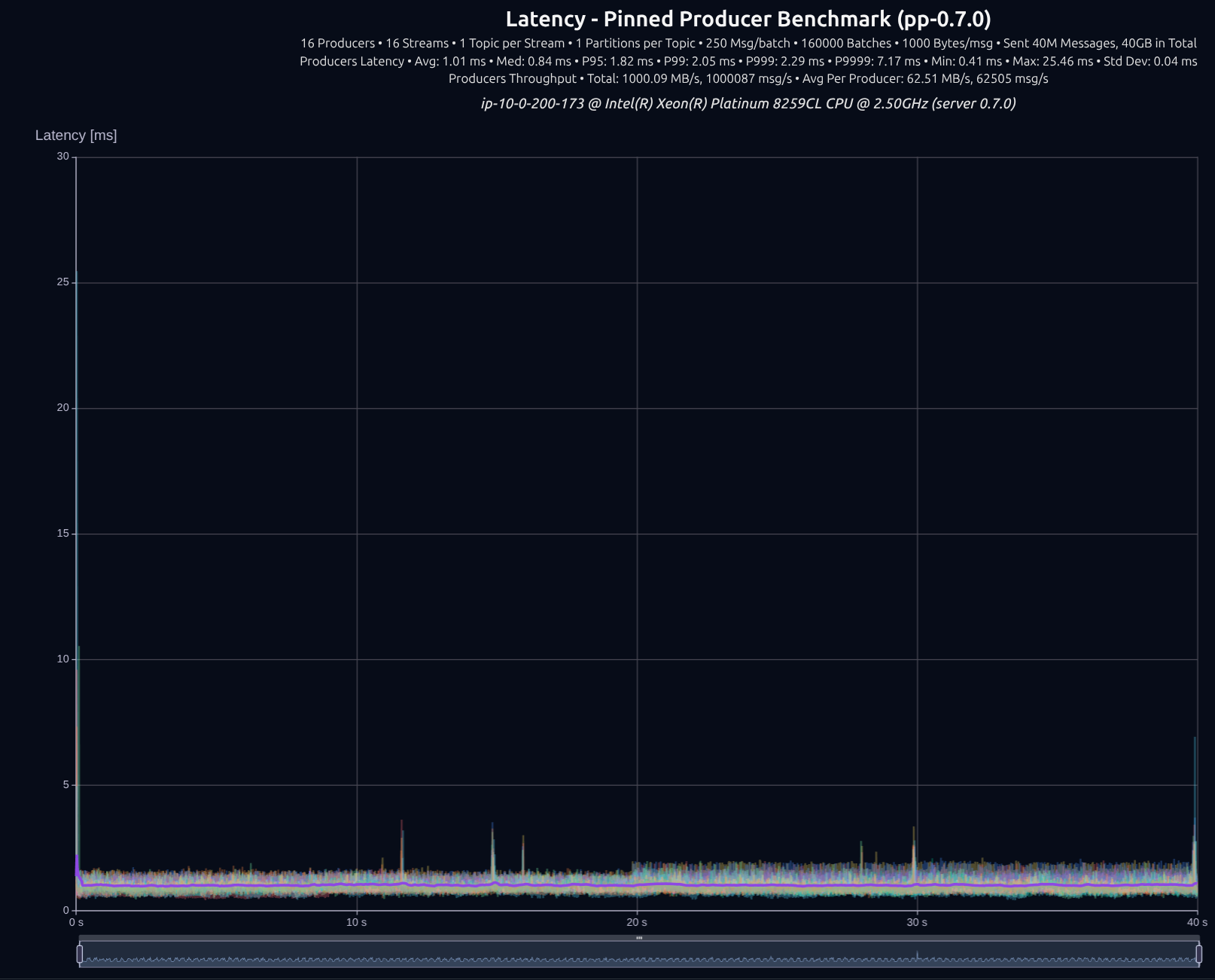
16 Producers × 16 Streams — 40 GB (40M msgs)
| Version | Throughput/node | P95 | P99 | P999 | P9999 |
|---|---|---|---|---|---|
| v0.5.0 | 1,000 MB/s | 2.52 ms | 3.01 ms | 3.54 ms | 86.30 ms |
| v0.7.0 | 1,000 MB/s | 1.82 ms | 2.05 ms | 2.29 ms | 7.17 ms |
| Improvement | — | -28% | -32% | -35% | -92% |
32 Partitions
v0.5.0 with tokio
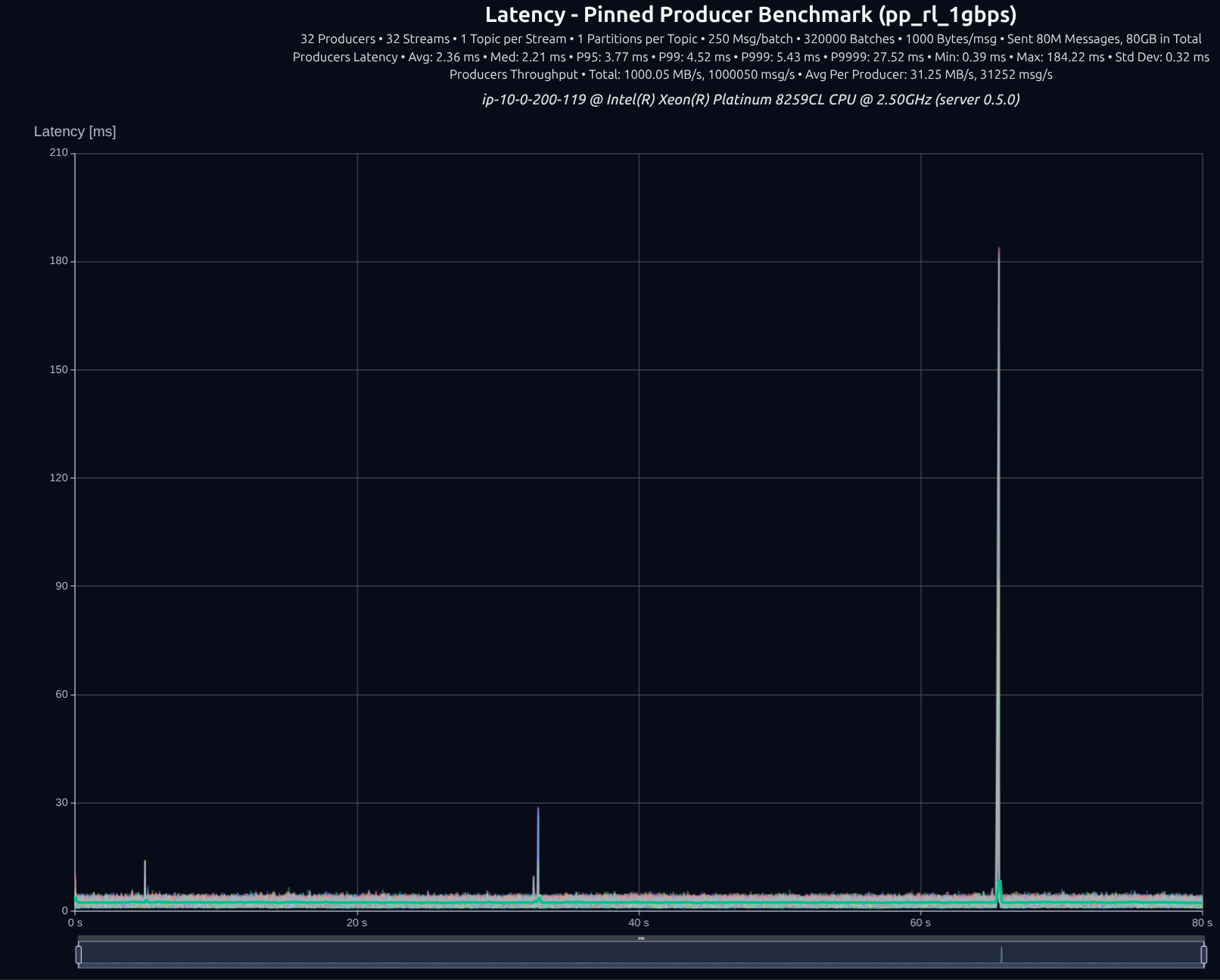
v0.6.1 with thread-per-core + io_uring
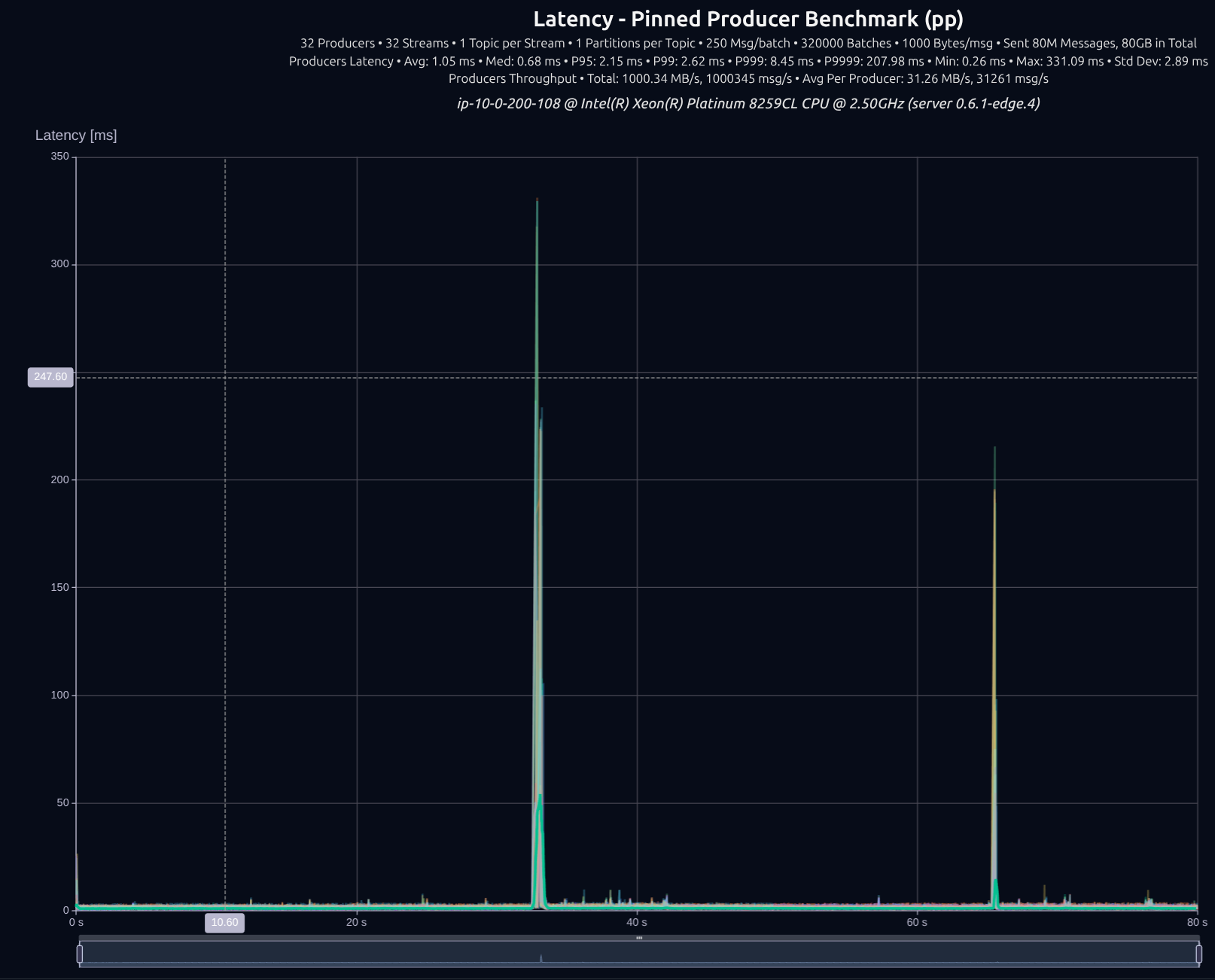
v0.7.0 with shared something
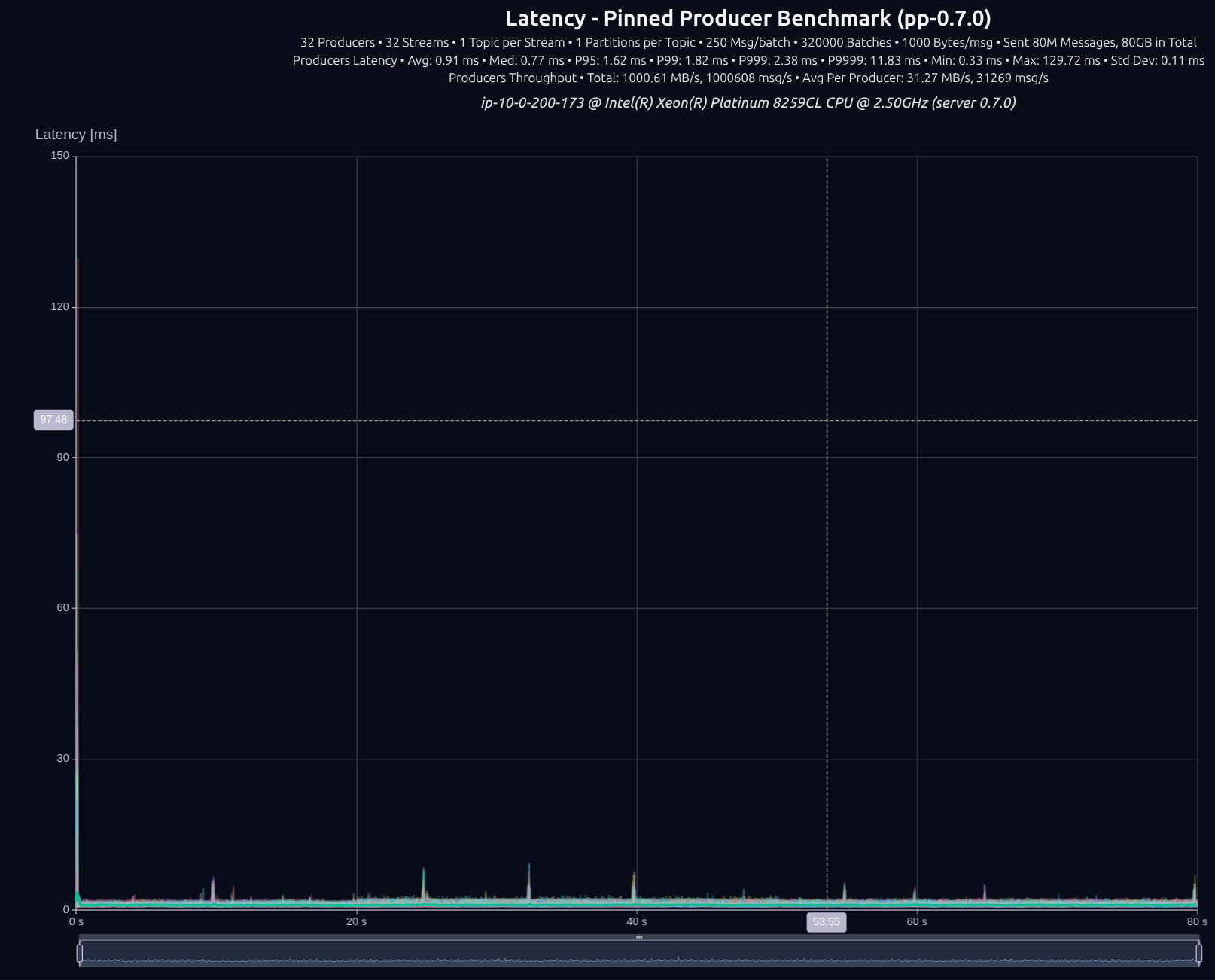
32 Producers × 32 Streams — 80 GB (80M msgs)
| Version | Throughput/node | P95 | P99 | P999 | P9999 |
|---|---|---|---|---|---|
| v0.5.0 | 1,000 MB/s | 3.77 ms | 4.52 ms | 5.43 ms | 27.52 ms |
| v0.7.0 | 1,001 MB/s | 1.62 ms | 1.82 ms | 2.38 ms | 11.83 ms |
| Improvement | — | -57% | -60% | -56% | -57% |
Strong Consistency Mode (fsync)
Flush the data to disk on every batch write.
16 Partitions
v0.5.0 with tokio
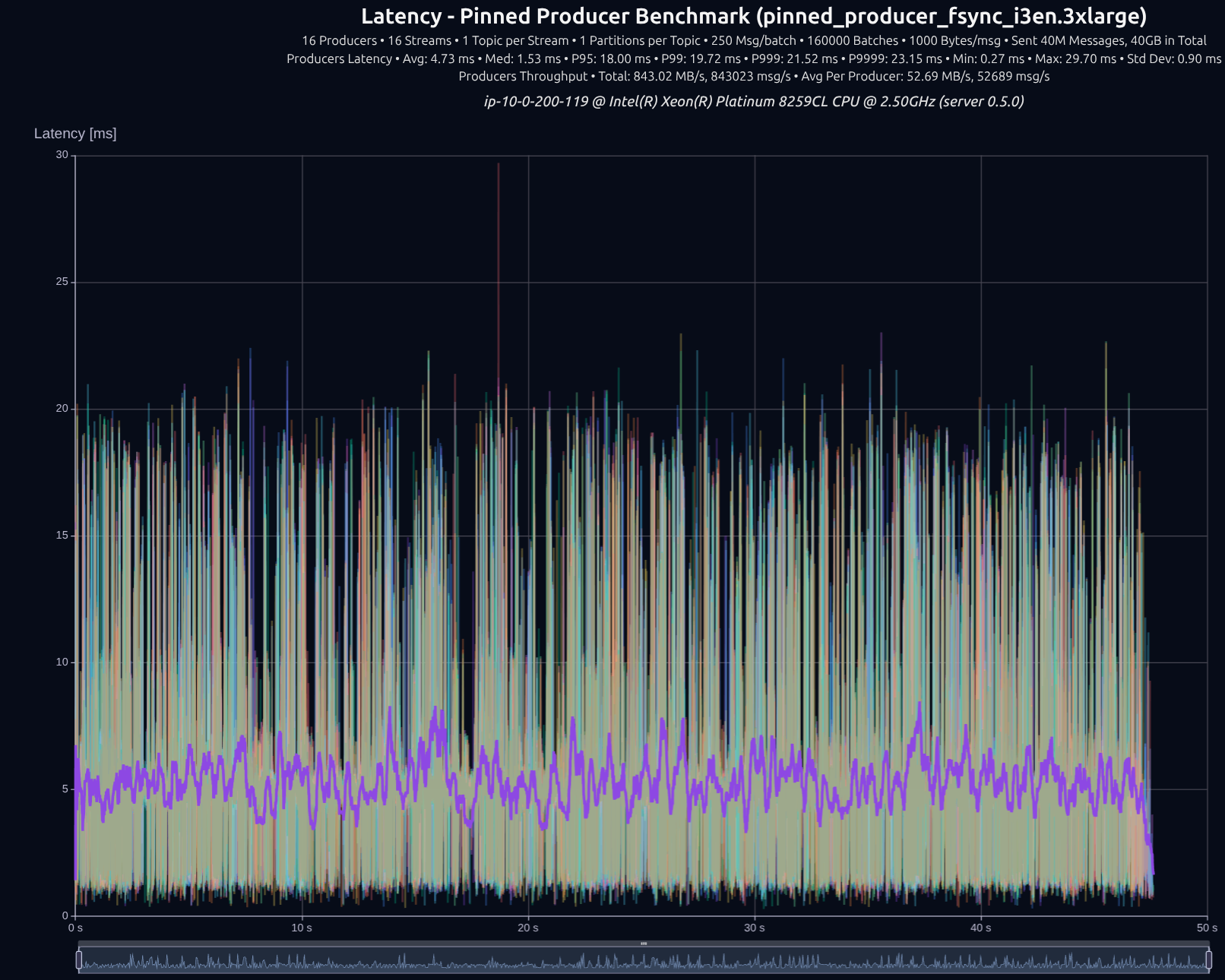
v0.7.0 with shared something
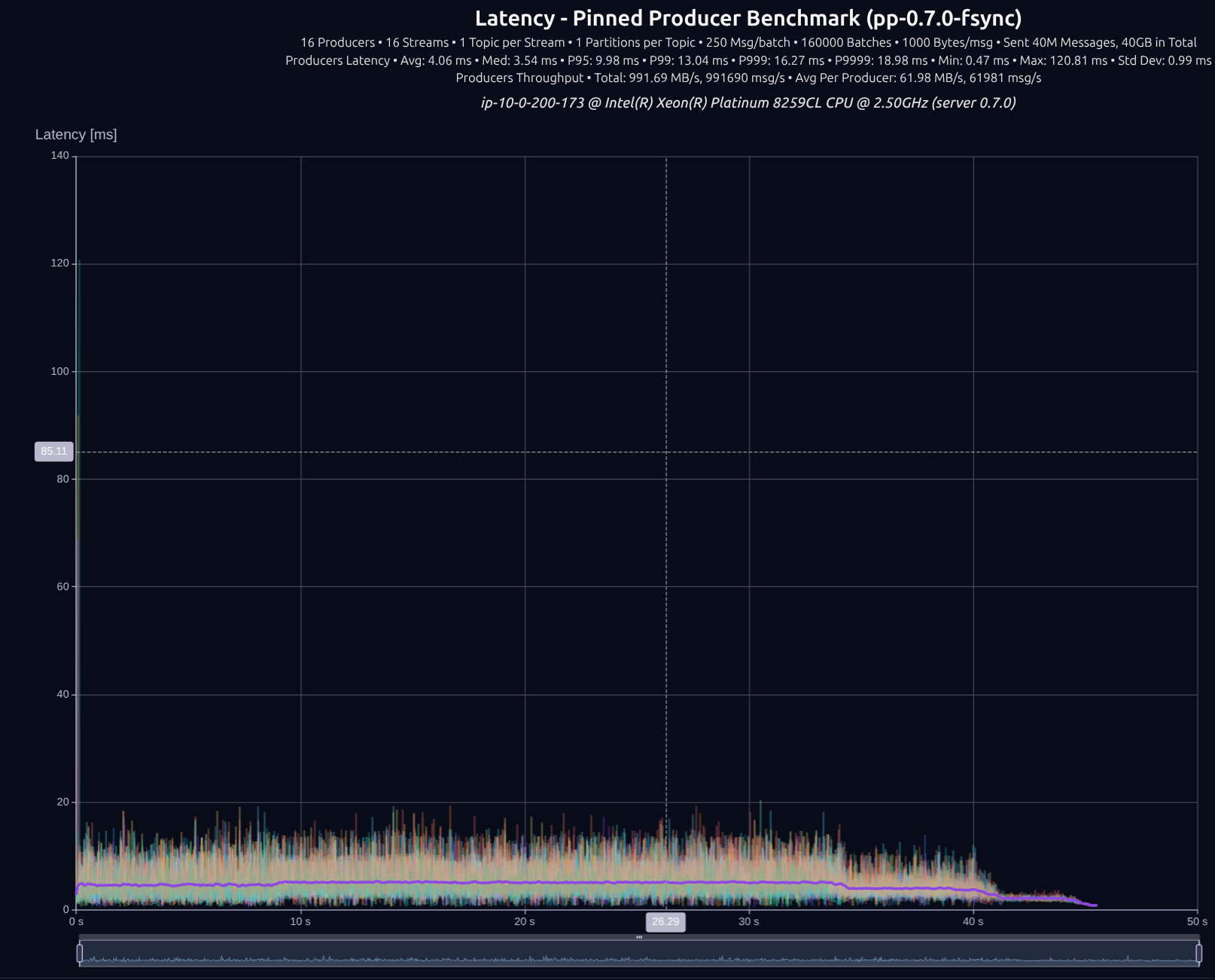
16 Producers × 16 Streams — 40 GB (40M msgs) — fsync
| Version | Throughput/node | P95 | P99 | P999 | P9999 |
|---|---|---|---|---|---|
| v0.5.0 | 843 MB/s | 18.00 ms | 19.72 ms | 21.52 ms | 23.15 ms |
| v0.7.0 | 992 MB/s | 9.98 ms | 13.04 ms | 16.27 ms | 18.98 ms |
| Improvement | +18% | -45% | -34% | -24% | -18% |
32 Partitions
v0.5.0 with tokio
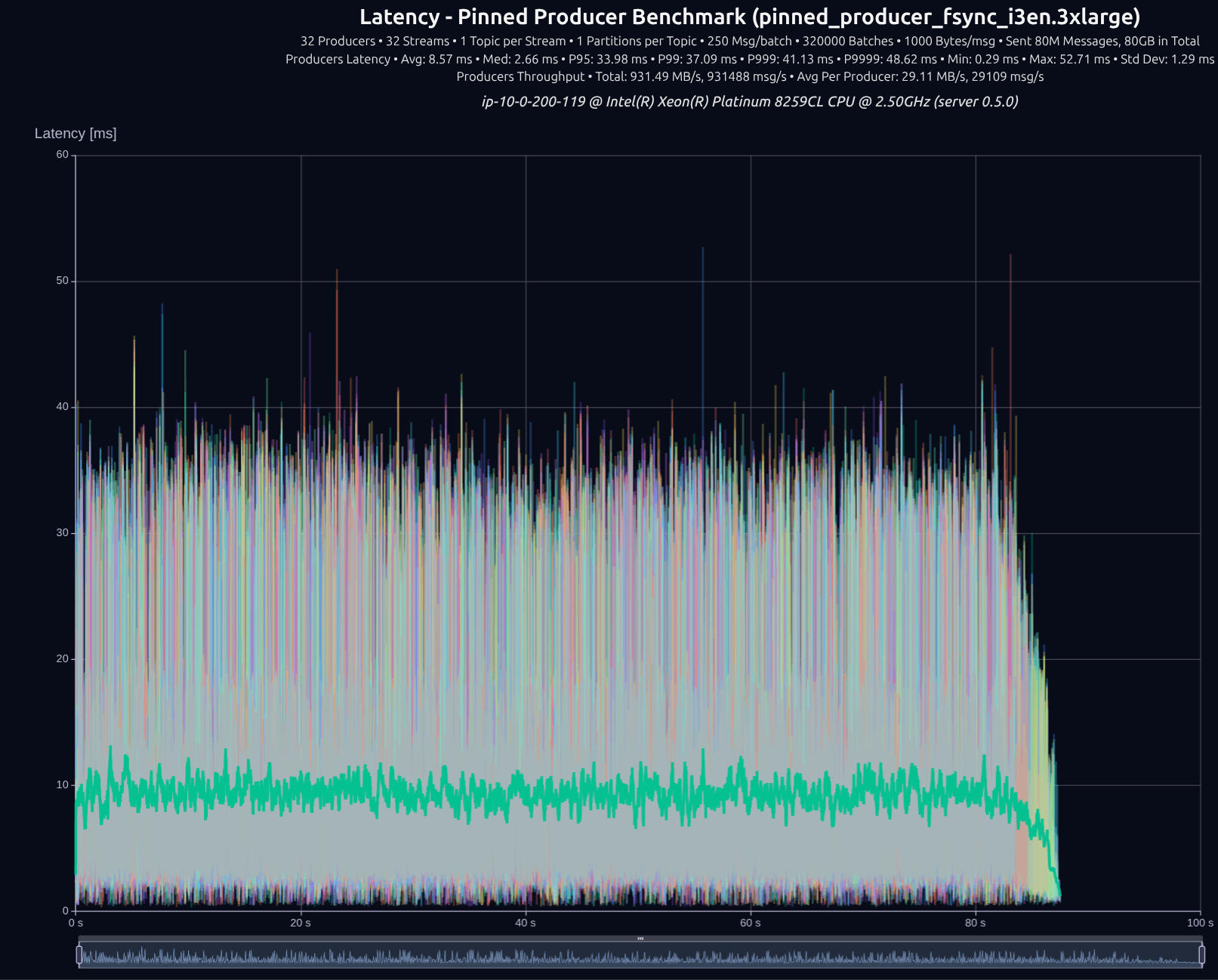
v0.7.0 with shared something
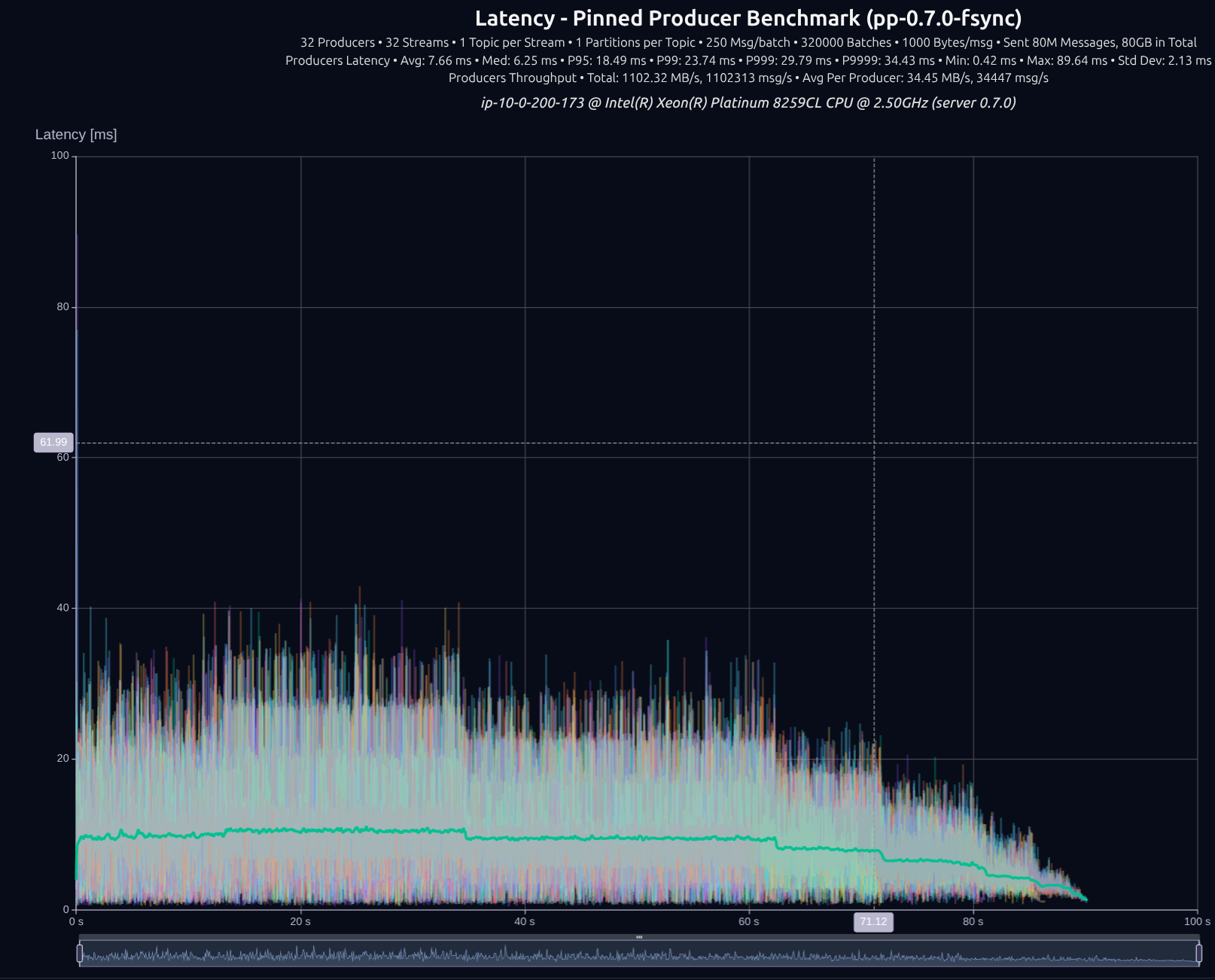
32 Producers × 32 Streams — 80 GB (80M msgs) — fsync
| Version | Throughput/node | P95 | P99 | P999 | P9999 |
|---|---|---|---|---|---|
| v0.5.0 | 931 MB/s | 33.98 ms | 37.09 ms | 41.13 ms | 48.62 ms |
| v0.7.0 | 1,102 MB/s | 18.49 ms | 23.74 ms | 29.79 ms | 34.43 ms |
| Improvement | +18% | -46% | -36% | -28% | -29% |
And what about reading the data?
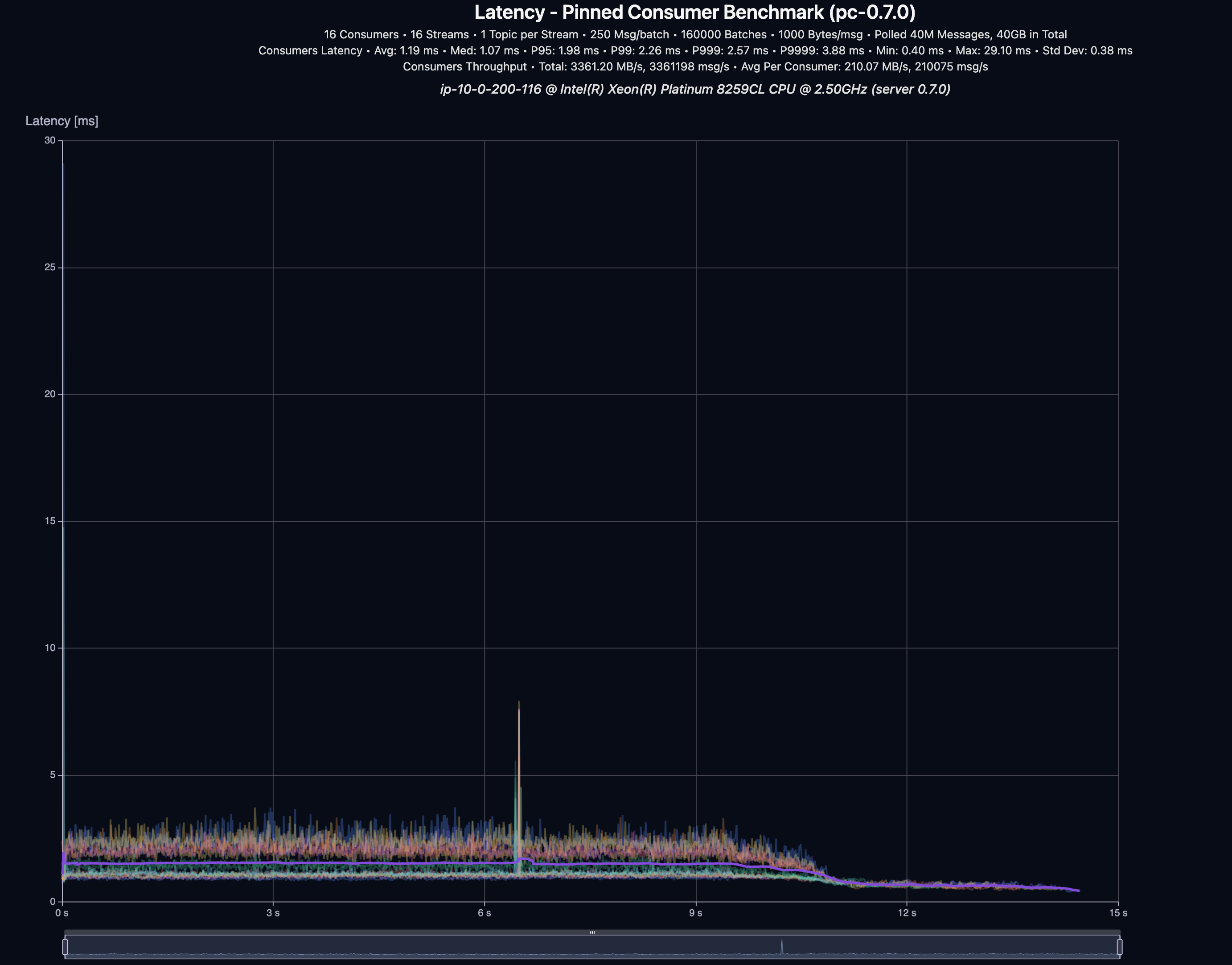
16 Consumers × 16 Streams — 40 GB (40M msgs)
| Throughput | P95 | P99 | P999 | P9999 |
|---|---|---|---|---|
| 3,361 MB/s | 1.98 ms | 2.26 ms | 2.57 ms | 3.88 ms |
Closing words
Finally, even though we went into significant detail in this blog post, we have only scratched the surface of what is possible, and several subsections could easily be blog posts on their own. If you are interested in learning more about thread-per-core shared-nothing design, check out the Seastar framework, it is the SOTA in this space. For now, we shift our attention to the ongoing work on clustering, using Viewstamped Replication.
Stay tuned a deep-dive blog post on that is coming, and we’re just getting started 🚀